





How are databases classified based on storage?
An operating system usually consists of two sets of memory
a. volatile
b. non-volatile memory
Volatile memories are faster than non-volatile memory due to their ease of access. Accessing main memory is ~85000 times faster than accessing the disk
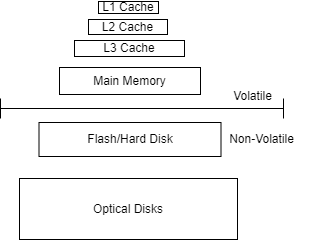
Based on where the databases store the data they can be classified into
a. In-Memory database system
b. Disk-based database system
What are in-memory database management systems?
In-Memory database systems store the data in main memory (RAM). They require fewer CPU operations thereby making the query response faster. They are usually optimized for specialized workloads
How do in-memory database systems persist the data?
Since main memory is volatile in nature any power outage or crash will result in data being erased from the memory. Such systems write the changes to a sequential log file which is then persisted in the disk. They also maintain backups which are snapshots of the database at a particular point in time also known as checkpoints. The backup and logs are used to restore the database upon startup.
Do they read the entire log content upon startup?
The database is restored from the last checkpoint and any additional operations present in logs are applied thereafter. This ensures the recovery does not require building the whole database from scratch.
Example of In-Memory database
a. SAP HANA
b. VoltDB
c. MemSQL
d. SQLite
What are disk-based DBMS?
Disk-based database management systems store data on disk. They support a broad set of workloads
Why is data moved from disk to memory?
Any computation on data can only be performed in memory. We need to load the data to memory to be able to read and make updates to it. For a disk-based database system, the copying to the main memory is abstracted by database buffers. Most database systems do not rely on an operating system to for moving the pages in and out of memory
Disk-based DBMS also use memory for caching to improve performance
Can the same data structure be applied to disk-based and memory-based storage?
Memory allows the data to be accessed via byte addresses making random access as fast as sequential access. While reading from disk the data has to be read in units of the block (a minimum chunk of data that can be read from disk) this makes random access more costly. Given the difference in access patterns, the data structures used by the two systems are different. While in-memory systems can choose from a variety of data structures, disk-based systems mostly rely on wide and short trees.
What is the difference in handling of data in main memory and disk?
Accessing data in memory is more performant than accessing data from disk. Programming for main memory is also relatively easier since much of the abstractions provided by the operating systems can be used as such. For a disk-based system, an additional management layer is required to manage the data formats, references, memory and fragmentation.
If it is easy and more performant to use memory then why do we not rely on memory-based DBMS always?
In-memory systems are fast but are also very expensive compared to disk, which makes them economically unviable for most use cases. There is also limited opportunity to scale such systems. The size of the main memory is not significantly growing any longer.
There are SSD-based DBMS that can achieve comparable performance if the working set fits in main memory (for example Umbra)
Resources
The above article captures the learning notes from